Notes pour l'examen intra - IFT-2008
Notes pour mon étude. À relire juste avant l'examen
09 h 00 à 11 h 50
235, rue Saint-Jacques (Cégep de Granby)
Local A-204
Feuille de note
Efficacité des algorithmes
Se mesure par la quantité de ressources utilisées
Ressources :
- Temps d'exécution : Temps que mets l'algorithme pour accomplir sa tâche
- L'espace mémoire utilisée : Nombre d'octets utilisés par l'algorithme pour accomplir sa tâche
- La bande passante utilisée : Nombre d'octets que l'algorithme doit échanger avec une entité pour accomplir sa tâche
Approche Empirique
Consiste à essayer l'algorithme sur différent jeux de données bien choisis
Avantages :
- Ne nécessite aucune connaissance en algorithmique
- Résultats réalistes pour les instances testées dans l'environnement de test
Inconvénients :
- Pas toujours généralisable aux instances non testées
- Coûteux et long (nécessite beaucoup de tests)
- Dépend de l'environnement d'exécution (le processeur, l'OS, la charge, l'implémentation, etc.)
Approche Algorithmique
Le coût d'exécution d'un algorithme est défini par le nombre d'opérations élémentaires effectuées durant son exécution
Une opération élémentaire est une opération non divisible
- Exemples valides :
- Comparaison (>, ==, <, etc.) de donnée élémentaire (int, float, char, double, etc.)
- Addition, multiplication, etc. de donnée élémentaire
- Exemples invalides
- Tri d'un tableau
- Recherche d'un élément
- Exécution d'un autre algorithme
- Etc.
Avantages :
- Résultat généraux, ne dépend pas de l'environnement d'exécution
- Estimation rapide et peu coûteuse (si t'es bon lmao)
Inconvénients :
- Nécessite la compréhension des notions algorithmiques (so git gud)
Notation (big) O
Détermine une borne supérieure éventuelle
Transitif, ce qui veut dire que si
𝑓(𝑛) ∈ 𝑂(𝑔(𝑛))
et
g(𝑛) ∈ 𝑂(ℎ(𝑛))
alors
𝑓(𝑛) ∈ 𝑂(ℎ(𝑛))
Définition formelle : 𝑓(𝑛) ∈ 𝑂(𝑔(𝑛)) s’il existe deux constantes positives 𝑛0 et 𝑐 tel que 𝑓(𝑛) ≤ 𝑐𝑔(𝑛) pour tout 𝑛 ≥ 𝑛₀.
MEANING
On dit que 𝑓(𝑛) ∈ O(𝑔(𝑛)) si 𝑓(𝑛) est bornée supérieurement par une fonction proportionnelle à 𝑔(𝑛) à partir d’un certain seuil 𝑛₀.
Décomposition :
- 𝑛₀ : Un point à partir duquel l’inégalité doit être vraie.
- 𝑐 : Une constante qui fixe une limite supérieure pour 𝑓(𝑛).
- 𝑓(𝑛) ≤ c𝑔(𝑛) pour tout 𝑛 ≥ 𝑛₀ : Cela signifie que pour les grandes valeurs de 𝑛, la fonction 𝑓(𝑛) croît au plus aussi vite que 𝑔(𝑛), à un facteur c près.
Interprétation :
La notation Big-O donne une estimation supérieure de la croissance de 𝑓(𝑛). Si 𝑓(𝑛) ∈ O(𝑔(𝑛)), alors 𝑔(𝑛) représente un majorant asymptotique de 𝑓(𝑛).
Exemple :
Si 𝑓(𝑛) = 5𝑛² + 3𝑛 + 2, alors on peut dire que 𝑓(𝑛) ∈ O(𝑛²) parce qu’il existe des constantes 𝑐 et 𝑛₀ telles que :
5𝑛² + 3𝑛 + 2 ≤ 𝑐𝑛²
pour un 𝑐 suffisamment grand et pour 𝑛 ≥ 𝑛₀.
Cela signifie que 𝑓(𝑛) a une croissance au plus quadratique pour les grandes valeurs de 𝑛.
Notation Ω (omega)
Détermine une borne inférieure éventuelle
AKA
Same shit, but inverted
Notation Θ (thêta)
Définition formelle : 𝑓(𝑛) ∈ 𝛩(𝑔(𝑛)) s’il existe trois constantes positives 𝑛₀, 𝑐₁, 𝑐₂ tel que
𝑐₁𝑔(𝑛) ≤ 𝑓(𝑛) ≤ 𝑐₂𝑔(𝑛)
pour tout 𝑛 ≥ 𝑛0.
Donc 𝑓(𝑛) ∈ 𝛩 𝑔(𝑛) si et seulement si f(𝑛) ∈ O(𝑔(𝑛)) et f(𝑛) ∈ Ω(𝑔(𝑛))
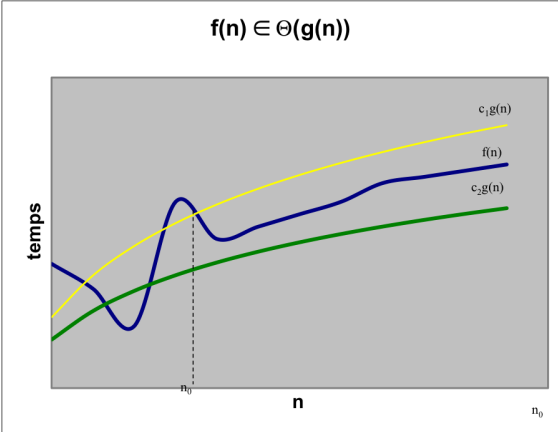
Basiquement, doit avoir le même "𝑔" et "𝑛" pour les deux autres notations, les "c" peuvent changer tho
Opération baromètre
Le temps d'exécution d'un algorithme = Nombre d'opérations élémentaires pour accomplir sa tâche
On ne cherche pas un chiffre précis, mais plutôt l'ordre de croissance, aka à quel point la taille de "𝑛" influence le temps d'exécution
Il suffit donc d'identifier une opération baromètre et de compter le nombre de fois que cette opération est effectuée en fonction de "𝑛"
L'opération baromètre est une opération élémentaire qui, à une constante près, est effectuée au moins aussi souvent que n’importe quelle autre opération élémentaire de l’algorithme.
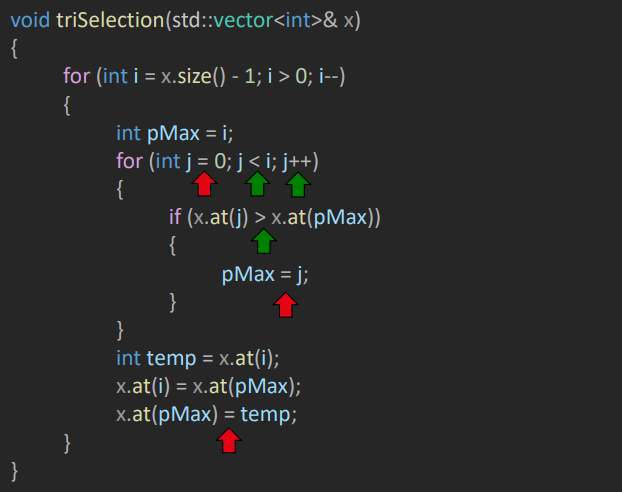
Les flèches rouges sont invalides :
- 1 : Cette opération n'arrive qu'une seul fois
- 2 : Il est impossible de déterminer combien de fois cette opération sera atteinte
- 3 : Cette opération est dans la première boucle, pas la deuxième, ce qui veut donc dire qu'elle n'arrive pas aussi souvent que n'importe quelle autre opération
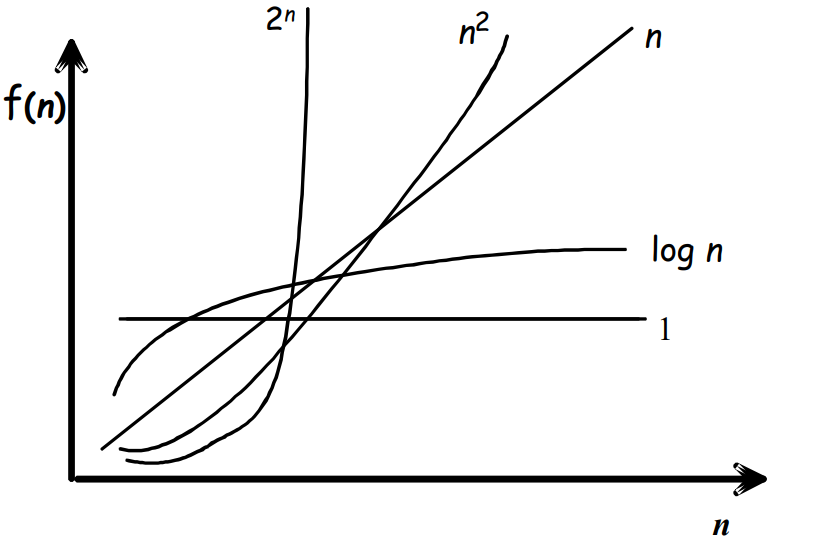
Classes de complexité
- O(1) : Indique un temps d'exécution constant, indépendant de 𝑛
- O(log(𝑛)) : Implique que toutes les données n'ont pas à être traitées
- O(𝑛) : Indique essentiellement que l'on doit effectuer un nombre constant d'opérations sur chaque donnée entrée
- O(𝑛²) : Implique un nombre d'opérations proportionnel à n, pour chaque donnée
- O(𝑛 * log(𝑛)) : Est typique des algorithmes diviser-pour-régner (ex : tri fusion)
- O(𝑛^a) pour a ≥ 1 : Algorithme à temps polynomial
- O(a^𝑛) : Algorithme à temps exponentiel, donc excessivement lent
- O(𝑛!) : Factoriel, aka le plus lent (1 + 2 + 3 + ... + 𝑛-1 + 𝑛)
Structures de donnée de base
Matière skippée dans les notes
Je saute par dessus toutes les structures de données de base puisque cette matière est déjà maîtrisé.
Je devrais revenir en arrière pour compléter cette documentation.
Graphes
Tout plein de points qu'ont relies ensemble (yeah)
Orienté : Les flèches ont un sens
- G = (𝑆,𝐴)
- 𝑆 est un ensemble fini des sommets
- 𝐴 ⊆ 𝑆 × 𝑆 , est un ensemble des arcs (flèches) qui relient les sommets
- Exemple
- 𝑆 = { 1, 2, 3, 4, 5 }
- 𝐴 = { (1, 2), (1, 3), (2, 3), (3, 2), (4, 4), (4, 5) }
Non orienté : Les liens sont bidirectionnels
Même chose à un détail prêt :
- A est une relation symétrique
- Si (1, 2) est présent, (2, 1) est nécessairement présent
Définitions
Adjacent : Un noeud adjacent à un autre veut dire qu'un arc existe entre les deux
- W est adjacent au noeud V si l'arc (V, W) existe
Chemin : Une suite de noeuds dans laquelle chaque paire de noeuds consécutifs est liée par un arc
- < 2,4 > et < 2,1,5,4 > sont 2 chemins allant de 2 à 4
Degré (ou arité) :
- Tout court : Le nombre d'arête (donc juste pour les graphes non orientés) dont ce sommet est une extremité
- De sortie : Le nombre d'arcs sortant (commençant) au sommet
- D'entrée : Le nombre d'arcs entrant (finissant) au sommet
Cycle : Un chemin dont l'origine est la même que la destination
Boucle : Cycle constitué d'un seul arc (sommet pointe sur lui-même)
Graphe acyclique : Graphe ne contenant aucun cycle
Puits : Noeud dont l'arité de sortie est 0
Source : Noeud dont l'arité d'entrée est 0
Graphes pondérés
Comme un graphe normal, mais chaque arc (u, v) possède une valeur numérique w(u, v)
Les graphes orientés et pondérés sont souvent appelés des réseaux
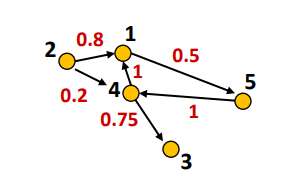
Exemple : l'arc (4, 3) possèe un poids de 0.75, soit w(4, 3) = 0.75
Longueur de chemin
La somme des poids des arcs constituant ce chemin.
Synonyme dans cette situation :
On peut donc trouver le plus petit chemin, ou encore le plus grand
Graphe connexe
Un graphe non orienté est connexe si et seulement si il existe un chemin etre n'importe quelle paire de sommets distincts du graphe
Aka, aucun sommet n'est isolé, il est possible de se rendre partout à partir de n'importe ou
Composante connexe : Le graphe n'est pas connexe, on se retrouve avec des sous-graphes connexes. Chaque sous-graphe est une composante connexe
Dans un graphe orienté, on parle plutôt de
- Faiblement connexe : Si on remplace les flèches par des arrêtes (transforme le graphe orienté en un graphe non orienté), le graphe modifié est connexe
- Non connexe : Up above is not true
- Fortement connexe : Il existe un chemin etre n'importe quelle paire de sommets distincts du graphe
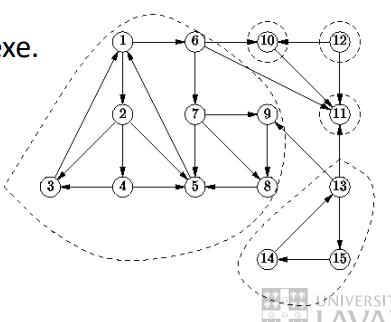
- Ce graphe est faiblement connexe
- Ce graphe comporte 5 composantes fortement connexes
Arbre
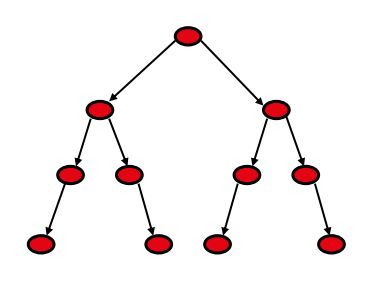
Un arbre est un graphe orienté, acyclique, faiblement connexe avec :
- 1 seul noeud source = racine
- Des noeuds puits = feuilles
- Degré d'entrée de tout noeud = 1, à l'exception de la racine (0)
- Il existe un chemin de la racine à tout autre noeud
Matrice de noeuds adjacents
Matrice d'adjacence
Définie par :
- 𝑀[𝑖][𝑗] = 1 si et seulement si (𝑖,𝑗) ∈ 𝐴
- 𝑀[𝑖][𝑗] = 0 si et seulement si (𝑖,𝑗) ∉ 𝐴

Avantages :
- Prends un temps en O(1) pour savoir si l'arc (i, j) existe
Inconvénients :
- Nécessite un temps en O(n) pour obtenir les voisins d'un sommet
- Nécessite un espace mémoire en O(n²)
Arité de sortie : Il suffit d'additionner une rangé pour avoir le degré de sortie
Arité d'entrée : Même chose, mais avec les colonnes
Matrice de valuation
Basiquement la même chose que la matrice d'adjacence, mais à la place de simplement mettre un "1" dans la matrice lorsque le lien existe, on met le poid de l'arc.
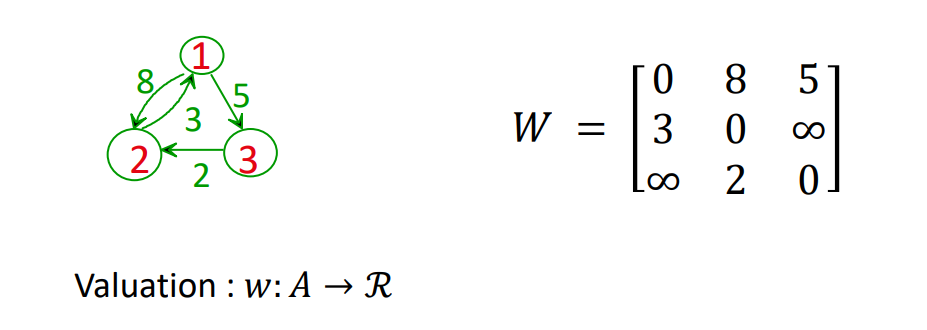
Définition formelle :
- 𝑊[𝑖,𝑗] = 0 quand 𝑖 = 𝑗
- 𝑊[𝑖,𝑗] = 𝑤(𝑖,𝑗) quand (𝑖,𝑗) ∈ 𝐴
- 𝑊[𝑖,𝑗] = +∞ quand 𝑖 ≠ 𝑗 et (𝑖,𝑗) ∉ 𝐴
Liste d'adjacence
Exemple d'un graphe non valué :
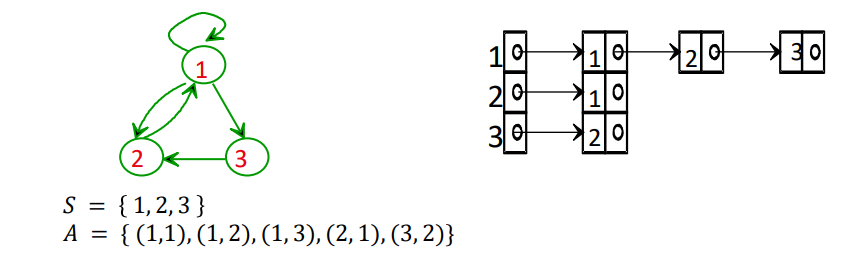
Exemple d'un graphe valué :
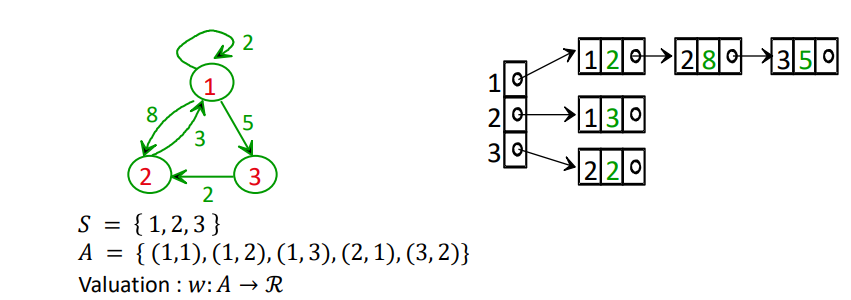
On ne fait que rajouter une boîte contenant le poids de l'arc
Forces et faiblesses
Forces
- Nécessite un espace mémoire en O(n + m) pour un graphe de n sommets et m arcs
- Ce qui est avantageux lorsque m << n² (graphe peu dense) par rapport à l'espace requise en O(n²) pour la matrice d'adjacence
- Un graphe est dense si m est comparable à n²
- Le parcours de tous les v(i) noeuds adjacents au sommet i se fait en O(v(i))
- Avantageux par rapport au temps en O(n) pour la matrice d'adjacence
Faiblesses
- L'accès à l'arc (i, j) se fait en temps O(v(i))
- Désavantageux par rapport au temps en O(1) pour la matrice d'adjacence
Conclusion
Le choix de l’implémentation (entre liste ou matrice) se fait donc en fonction de ces compromis.
- Quelle est l'utilisation qu'on va faire de ce graphe ?
Le plus souvent, c’est la liste de successeurs qui est préférable.
Parcours d'un graphe
De nombreux algorithmes relatifs aux graphes nécessitent une procédure qui permet l'examen systématique des noeuds d'un graphe, une et une seule fois
Possibilité de présence de cycles, alors il faut marquer les noeuds déjà visités pour éviter de revenir continuellement sur les mêmes noeuds
Parcours en profondeur (Depth-First Search: DFS)
Algorithme :
- Initialiser (mettre à faux) une marque associée à chaque noeud
- Empiler et marquer (à vrai) le noeud de départ
- Tant et aussi longtemps que la pile n'est pas vide :
- Dépiler un noeud et lui faire le traitement voulu (par exemple, afficher sa valeur à l'écran)
- Pour chacun de ses voisins qui n'est pas marqué
- Le marquer (à vrai)
- L'empiler
Remarques
- On ne peut pas visiter les noeuds inaccessibles à partir du noeud de départ à l'aide de cet algorithme
- Il suffit de recommencer à partir d'un noeud qui n'a pas été marqué par l'algorithme
Parcours en largeur (Breadth-First Search: BFS)
Basiquement la même chose, mais avec une file plutôt qu'une pile
Algorithme :
- Initialiser (mettre à faux) une marque associée à chaque noeud
- Enfiiler et marquer (à vrai) le noeud de départ
- Tant et aussi longtemps que la file n'est pas vide :
- Défiler un noeud et lui faire le traiter
- Pour chacun de ses voisins qui n'est pas marqué
- Le marquer (à vrai)
- L'enfiler
Algorithmes de parcours de graphe
Kosaraju
TODO
Dijkstra
Principe : Approche gloutonne
Ne fonctionne qu'avec des poids positifs
Algorithme :
- Initialisation
- Distance de la source = 0
- Autres distance = ∞
- Sélectionner le sommet non traité avec la plus petite distance connue
- Mettre à jour les distances des voisins (relâchement)
- Répéter jusqu'à ce que tous les sommets soient traités
Relâchement : Calculer la distance de tous les sommets voisins
Complexité :
- O(n^2) avec matrice d'adjacence
- O((n+m)log(n)) avec tas min.
Ballman-Ford
Pincipe : Itérations successives de relâchement des arêtes
Gère les poids négatifs (mais pas les cycles négatifs)
Algorithme :
- Initialisation
- Distance de la source = 0
- Autres distance = ∞
- Répéter n - 1 fois : relâcher toutes les arêtes
- Vérifier la présence de cycles négatif
Complexité :
- O(nm)
- Plus lent que Dijkstra, mais plus général
Floyd / Warshall
TODO
Retour